
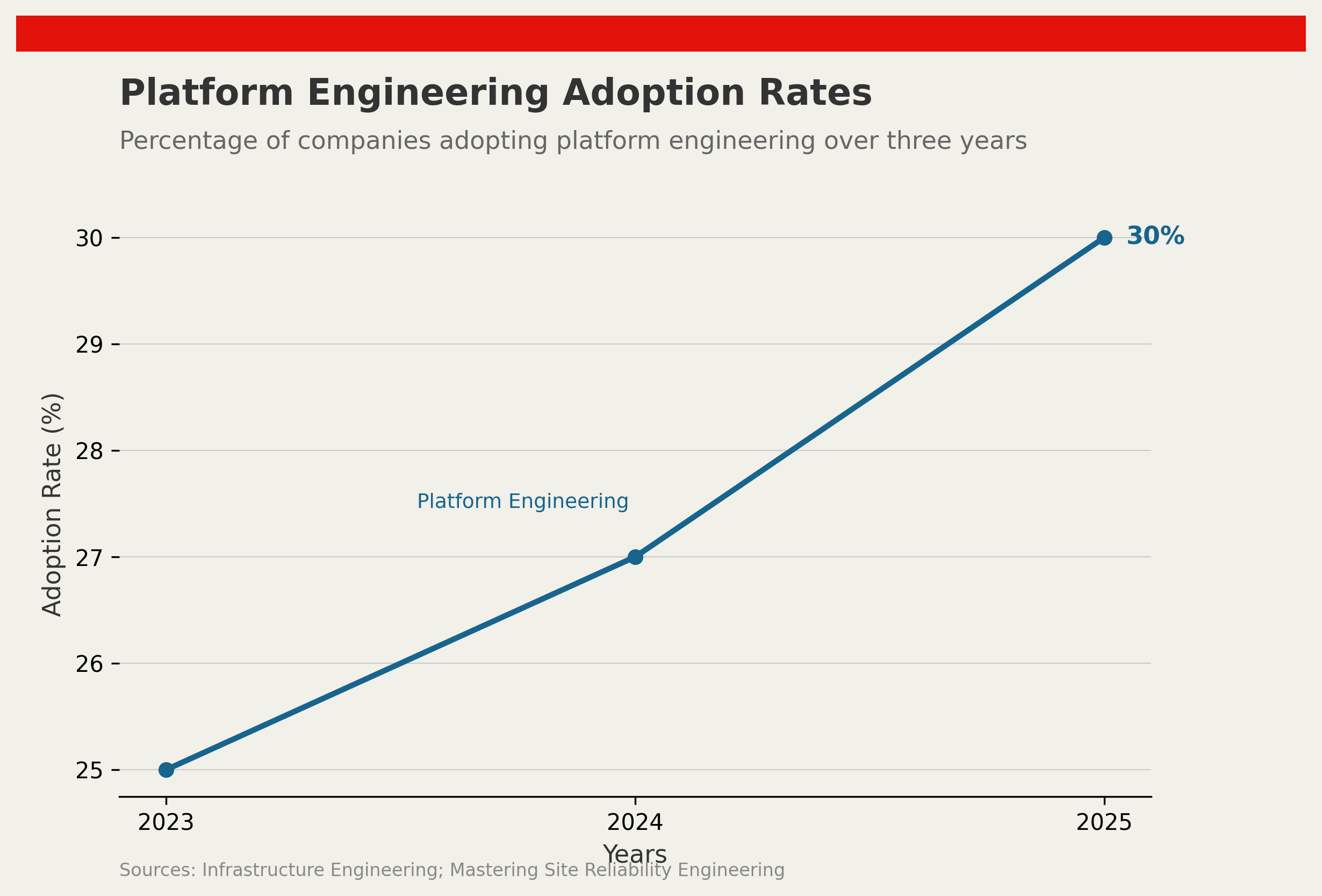
Only 30% of companies fully realise the benefits of platform engineering within the first three years of adoption. Despite significant capital and engineering time invested, organisations repeatedly find that the gap between what platform engineering promises and what it delivers in practice is wider than expected. The culprits are rarely technical.
 Source: Infrastructure Engineering research, 2025
Source: Infrastructure Engineering research, 2025
The Misunderstanding at the Core
Platform engineering sits at the crossroads of software development and operations. Its promise is straightforward: centralise internal infrastructure, reduce cognitive load on product teams, and accelerate delivery through self-service tooling. The reality is that organisations often cannot agree on what the role actually means.
Without a clear definition, platform teams get pulled in conflicting directions. Some are asked to build and maintain Kubernetes clusters. Others become an internal consulting function. Still others are treated as a second helpdesk. This role ambiguity produces weak integration and chronic underutilisation, ensuring the investment never compounds.
Developer portals are a case in point. Approximately 45% fail to meet user expectations, according to research on internal developer platforms conducted in 2025. The failure mode is almost always the same: the portal is built for the team that built it, not the developers expected to use it. Insufficient usability research, sparse documentation, and no feedback loop ensure that adoption stalls within the first quarter of launch.
Cultural Resistance Outlasts Technical Debt
More than 60% of platform engineering initiatives encounter significant cultural pushback. This figure should not surprise anyone who has tried to change how an engineering organisation works. Technical transformation is a proxy for organisational transformation, and organisations resist the latter far more stubbornly than they resist upgrading a runtime.
The pattern is consistent. When platform teams introduce golden paths, mandatory CI templates, or centralised secrets management, engineers who have spent years building their own tooling perceive it as a loss of autonomy rather than a reduction in toil. The resistance is rarely explicit. It manifests as slow adoption metrics, polite non-compliance, and a quiet proliferation of shadow tooling that defeats the purpose of standardisation.
This is not a failure of the technology. It is a failure of change management. Organisations that treat platform engineering as a purely technical undertaking miss the larger challenge: earning the trust and buy-in of the developers the platform is meant to serve. Internal developer experience surveys, public roadmaps, and lightweight feedback mechanisms are not nice-to-haves — they are the adoption mechanism.
Tooling Gaps Compound the Problem
Personnel and cultural barriers are compounded by infrastructure that was not designed to support the self-service model platform engineering requires. Many organisations launch platform engineering initiatives without auditing whether their existing tooling can deliver on the abstraction layer the model depends on.
The result is partial implementation. Developers gain access to a portal that cannot provision real infrastructure. The golden path works for a subset of use cases and breaks for everything else. On-call rotations pile up because the platform cannot self-heal. In these environments, the platform becomes a source of friction rather than a relief from it.
Addressing this requires sequencing. Platform engineering adoption should begin with a narrow, well-scoped capability that can be delivered reliably — a single runtime, a single deployment workflow, a single secrets store — rather than an ambitious abstraction across the entire stack. Incremental wins build trust. Overambitious launches that under-deliver destroy it.
Measuring What Actually Matters
A recurring observation from platform engineering post-mortems is that teams measure the wrong things. Lines of platform code written, number of services onboarded, and portal page views are easy to report but poorly correlated with value delivered.
The metrics that matter are downstream: deployment frequency for teams on the platform versus off it, change failure rate, mean time to restore, and developer satisfaction scores. These require baseline measurement before the platform launches, which most organisations skip, making it impossible to demonstrate impact after the fact.
Without that evidence, platform teams struggle to justify continued investment — even when the platform is working. The 30% adoption figure cited above may be an undercount of value delivered, because teams that never measured the counterfactual cannot prove what they saved.
The Path Forward
Platform engineering will fulfil its potential only where organisations treat the adoption challenge as seriously as the technical challenge. That means defining the platform team’s mandate clearly before the first line of infrastructure-as-code is written, investing in developer experience research as a first-class activity, sequencing capabilities from narrow to broad, and measuring outcomes that connect to engineering throughput rather than platform activity.
The tools are not the constraint. The discipline of building for your users — even when your users are your colleagues — is.
References
- Infrastructure Engineering: A Still Missing, Undervalued Role in the Research Ecosystem, arXiv, 2025. Available at: arxiv.org/abs/2405.10473
- Mastering Site Reliability Engineering in Enterprise, Springer, 2025. Available at: link.springer.com
- Internal Developer Platforms: A 2025 Benchmark Report, CNCF TAG App Delivery, 2025. Available at: tag-app-delivery.cncf.io






Discussion